Reproducibility is one of the key aspects to develop reliable research. The swift grow of new technologies to store and process data have been pushing limits and helping in data analysis. Cloud computing systems, such as Kubernetes, can help in the distribution and orchestration of data analysis pipelines or workflows. Some of these pipelines render an enormous amount of data and it is compelling to perform efficient computation.
The goal of this project is to develop a framework on top of Kubernetes that is able to handle efficiently with modifications in data and/or code in common data scientific workflows. It means, this layer must be able to contrast files and data in a repository, extract which of them were modified and what are the tasks that must be run again due to those changes. This framework is intended to deal with slow changes in data or code and it does not aim to be a streaming solution. The solution was design to be an API that can be called through http request. The goal is to have a framework which does not impose any restriction about the programming language required by intermediate tasks, it means, a job can use different languages and this behavior will be encapsulated in Docker images.
A job is a set of tasks that need to be executed in a predefined order. Tasks depends on data and data might be generated by previous tasks and it leads to indirect dependencies among tasks. Thus, a job can be modeled by a DAG (directed acyclic graph) where the nodes fall into two distinct categories, task or data. Edges appears just between data and tasks and their direction determine if the data is an input or an output of the task. The figure below illustrates an example of a job and note that edges happen just between data and tasks. In this context data can be a table, a chart, a set of parameters, a single number representing the accuracy of a model for example.
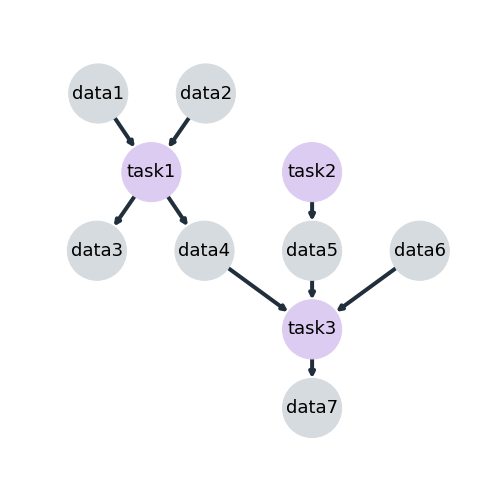
In order to build our layer that is able to handle wisely with alteration in tasks or data, it is important take in account the following aspects:
-
task1 and task2 are independent and can be run in parallel or even in different machines
-
task3 depends on data generated by task1 and task2 then it must wait until data4, data5 are available
-
if the file data6 is modified, then just the task3 should be impacted and re-run
-
if the script of task1 is modified, then task1 and task3 should be re-run
As cited above, the framework should be able to handle different environments and it means that task1 can be written in python2.7 and task2 in python3.6 or R for instance. It will give flexibility to use a vaster ecosystem of tools and libraries. In addition, it eliminates some drawback in scientific contribution since researchers with different backgrounds and skill set should be to work independently in the same project.
Argo is a framework which runs nativity pipelines on top of Kubernetes cluster. The dependencies are passed to Argo in a similar way that is done in Airflow, it means, in terms of task dependency and not on data dependency. Besides that, this framework is fault tolerant and clever enough to run independent tasks in parallel and has a nice web interface to follow-up the job’s execution. The snippet below gives how the recipe of the cited job would be specified:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: job-
spec:
entrypoint: job
templates:
- name: task1
container:
image: task1-image
command: <task1>
- name: task2
container:
image: task2-image
command: <task2>
- name: task3
container:
image: task3-image
command: <task3>
- name: job
dag:
tasks:
- name: task1
template: task1
- name: task2
template: task2
- name: task3
dependencies: [ task1, task2 ]
template: task3
Even though Argo is not capable to deal with partial execution of jobs (or subdag), it showed to be a good alternative because it integrates very well with Kubernetes and a feasible solution to work around this issue is to create a layer just before submit workflows to Argo. The responsibility of this new layer is to take care of the management of which tasks needed to be run and generate recipes on the fly.
The goal of this blog post is to present a project that builds a layer on top of Kubernetes (using Argo) that is clever enough to discovery changes in these pipelines (whether in code or in data) and just re-run tasks that were impacted.
In summary we are looking for:
-
nice integration with Kubernetes
-
ability to run independent tasks in parallel
-
be able to handle with tasks with different environments
-
be fault tolerant
-
run just tasks that were affected by some modification in data or code
-
have a simple interface with the final user (researchers)
Argo has already implemented 1, 2, 3 and 4 and our goal for this project is to build a layer that is able to handle with 5 and 6. This layer was designed to be a REST service deployed on Kubernetes cluster called workflow-controler and it was written in Python. workflow-controler has an endpoint /run that receives a POST request with job_name and job_url where job_name is a string containing the job’s name and job_url is a string with the URL of the repository.
Additionally, in order to describe the dependency structure and what is needed to run for each task, a file called *dependencies.yaml must be exists inside the repository. This file is basically a dictionary where each key is a task and the values are dictionary with inputs, outputs, image and command for each task. The code below shows how the job must be specified:
task1:
inputs:
- data1
- data2
outputs:
- data3
- data 4
image: <image task1>
command: <task1>
task2:
inputs:
outputs:
- data5
image: <image task2>
command: <task2>
task3:
inputs:
- data4
- data5
- data6
outputs:
- data7
image: <image task3>
command: <task3>
The storage chosen for both persistent and temporary was Minio which is a distributed object storage server. This storage was adopted because it is easily deployable in Kubernetes cluster through helm client and implements Amazon S3 v2/v4 API which turns any replacement to other storages with the same protocol effortless.
An overview of all steps needed to run a subdag is described by the following gif:
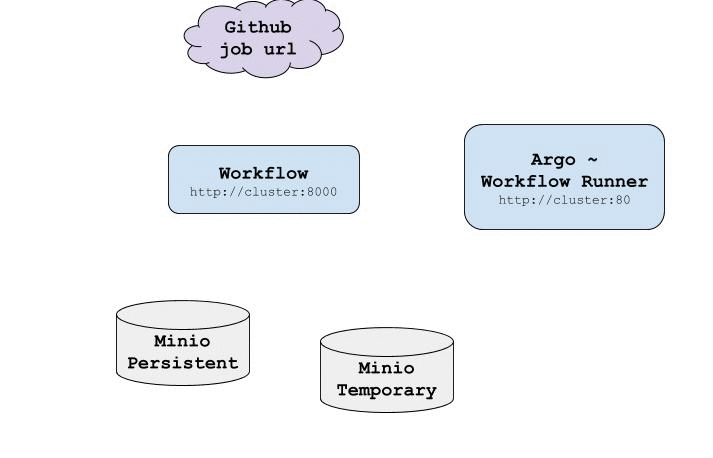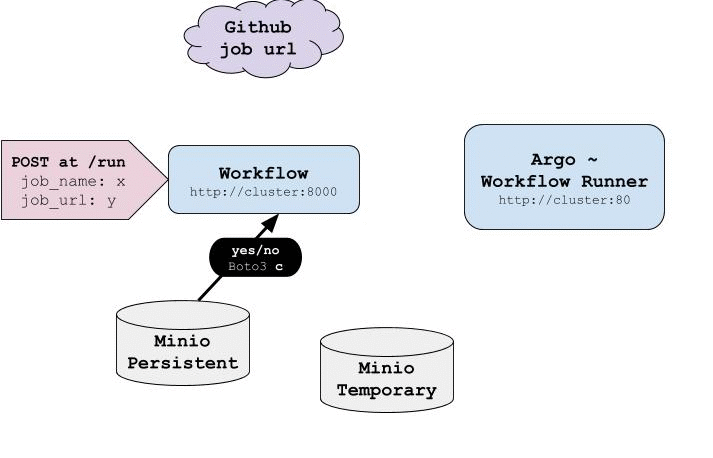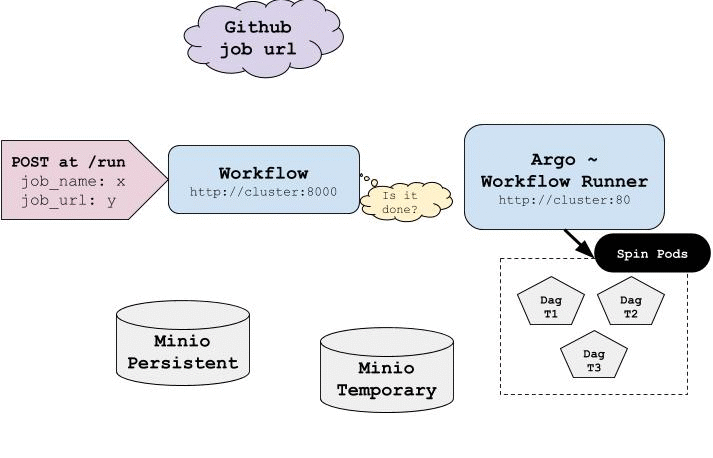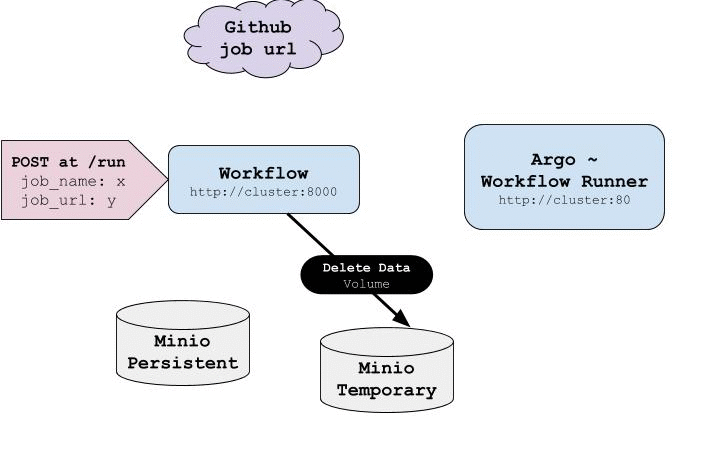
-
saves the job code and data files in a temporary storage
-
checks if the job is valid and if it is already registered in the persistent storage
-
checks if dependencies structure is valid and compares files
-
generates subdags based on the files that have been changed and combine them
-
renders the final subdag into an \texttt{yaml} file that argo is able to process
-
submits partial job to \texttt{Argo} and wait until the task is finished
-
moves files to the persistent storage
Here you can access the code and full report.