Code is available here.
The goal of this project is to be some kind of tutorial to get up a cluster in AWS to run a predictive model as a REST service.
Besides that, the stacking of this tutorial allows have multiple version of the model which is great to retrain and do A/B test.
In the end of Step by step you’ll have a endpoint of cluster of machines in AWS to run the model and
access the results. The request’s inputs and model’s outputs will be also available in a postgres database.
The entire stack is configured to run according to the amazon’s free tier rules, so if still have free tier, you won’t be charged.
The scripts will use mainly:
-
AWS command line client to communicate with AWS application to run our application
modelapp -
Docker command line to build images that will run inside each machine of the cluster
-
jqto parse json outputs fromawscli
The web framework in this tutorial is Flask and the model running is a simple model using iris dataset,
but could be other as long it respects the contracts with the database and endpoints.
That means, changing the web framework and model or even the programming language will not change the way that the service is deployed.
- NOTE: The scripts are optimized to work with MacOS and if you hold a Linux or Windows, some modifications will be suggested.
Overview of AWS stack
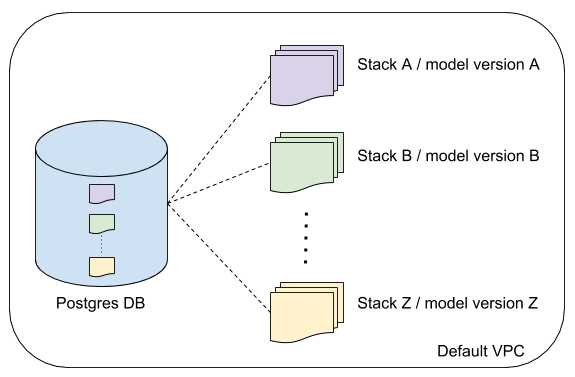
Each model version has a stack that contains:
-
Elastic Load Balancer to distribute the networking load among the machines inside the cluster
-
Security group associated with the cluster
-
Autoscaling group to scale the number of instances automatically
-
Task definition and service definition
For each model version is created 2 tables in the database, one with the inputs of the requests and another with the outputs
identified by {inputs_version, outputs_version}. The entire stack with be on your default VPC that is created for every
zones when you open an account.
Suppose that you want to deploy a model but before you need to do an A/B test comparing the old version with the new one,
so you’ll need to keep up 2 stacks and this infra allows scale up each model independently.
Main Requirements
The requeriments described here is to setup a cluster in AWS, but for others minor tasks the requeriments will be given in each section.
1. AWS account
Create a free account in AWS under the free tier.
2. Local Virtual Machine
If don’t hold a Linux please download and install VirtualBox
This is required to build, use and manage docker, which is a way to package software to run anywhere.
- NOTE: More informations can be found here
3. Docker
For MacOS:
$ brew install docker
$ brew install docker-machine
- NOTE: For others operational systems check here.
Check if they are installed successfully:
$ docker --version
$ docker-machine --version
If you don’t hold a Linux, you also have to create a default machine to use docker, so run:
$ docker-machine create
$ docker-machine ls
- NOTE: More informations can be found here and a blog post explaining the interaction between docker and VM can be found here
4. Python 3.6
Install python to train your model.
$ brew install python3
5. AWS command line
In order to install AWS command line, you have to install first python and then you can install awscli through pip.
Python’s version is not important in this case but I would recommend use python3.6.
For MacOS:
$ pip3 install awscli
6. jq
jq is a useful tool to manipulate json and as awscli will always return the results in json format
it will helpful to parse them. For MacOS:
$ brew install jq
- NOTE: For others operational systems check here
Step by step
1. Setup of environment variables
In order to run this project you will need to setup some environment variables as AWS keys, user and password
.
The script below should be filled and saved in /secrets/env-variables.sh.
#!/usr/bin/env bash
export AWS_ACCESS_KEY=XXXXXXXXXXXXXXXXXX
export AWS_SECRET_KEY=XXXXXXXXXXXXXXXXXX
export AWS_DEFAULT_REGION=XXXXXXXXXXXXXXXXXX
export DBMASTERUSER=XXXXXXXXXXXXXXXXXX
export DBPASSWORD=XXXXXXXXXXXXXXXXXX
export ARTIFACTS_AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY
export ARTIFACTS_AWS_SECRET_ACCESS_KEY=$AWS_SECRET_KEY
export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_KEY
export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY
export ECS_STACK_PREFIX=modelapp
export DOCKER_REPOSITORY_NAME=modelapp
export KEY_VALUE_PAIR_NAME=modelapp-key
export DB_NAME=modelapp
You must load the the variables above before start running the project:
$ . ./secrets/env-variables.sh
If you don’t have AWS key you can check how to get it here
2. Bootstrap
To run the Flask application, we will need to:
-
Create a repository to store the docker images with the application and its dependencies
-
Create a key-value pair to enable access to the cluster’s machine, this key will be download to the folder
secrets/modelapp-key.pem -
Create a database to store the inputs and outputs of our application using the receipt
cf-db.json
The script below will make sure that everything has been created and if is not, will create.
$ bash bootstrap.sh -r $DOCKER_REPOSITORY_NAME \
-k $KEY_VALUE_PAIR_NAME \
-d $DB_NAME \
-u $DBMASTERUSER \
-p $DBPASSWORD
The database creation might take some minutes, so just jump to the next step if the database creation is completed.
You can check the stack’s status logging here and then go to services > cloudformation
and wait until the Status of the stack db-modelapp become CREATE_COMPLETE.
The requirements to run it are {1, 4, 5}.
3. Deploying your application
Make sure that your VM is running or run it to start the VM:
$ docker-machine start default
The script below will:
-
Check if there is already a docker image or a stack with the current version. The version will be extracted from the
VERSIONfile, so if there is already this version deployed you can either update the version or runrevert-deploy.sh -
Train the model and save the model’s output in
resourses/model -
Build a docker image with the new version’s model and package all the dependencies of your application
-
Push this image created to the repository previously created in
bootstrap.sh -
Create a stack with a cluster of machines running the service specified in the pushed docker image using the receipt
cf-ecs-cluster.json
$ bash train-and-deploy-it.sh -r $DOCKER_REPOSITORY_NAME \
-k $KEY_VALUE_PAIR_NAME \
-d $DB_NAME \
-u $DBMASTERUSER \
-p $DBPASSWORD
If you made some change in the code of your application, for instance, you included one variable more then you should fix the tests,
bump the VERSION and then deploy-it.sh again.
The dependencies required to run it are {1, 2, 3, 4, 5}.
4. Getting Endpoint (DNS)
Get the URL or endpoint of your application.
$ aws cloudformation describe-stacks --stack-name modelapp-`cat VERSION` | jq '.Stacks[].Outputs[].OutputValue'
How to access your deployed model
Sending requests to the application
Install the library requests:
$ pip3 install requests==2.18.4
and then run you can run the script to make requests:
$ python3 resources/populate_db.py http://my-endpoint/
If you are running locally (non-dockerized or dockerized), the endpoint should be localhost:8080/run/.
If you are running in AWS, get the endpoint in the step 4 in Step by step.
Running the application adhoc
Sometimes is painful spin a stack just to run some tests or retrain your model. There are two ways that you can test your application, the first one is activate the virtualenv and then running the application and the other is building the docker image and running the container with the application.
The first option:
$ bash modelapp/bootstrap-python-env.sh
$ . modelapp-python-env/bin/activate
$ python3 modelapp/src/modelapp/manage.py runserver --host 0.0.0.0 --port=8080
The second option:
$ docker build -t mytest .
$ docker run -it -p 8080:8080 mytest
to check if they are actually running curl localhost:8080 should return 200.
Trainning and running the application adhoc
If you made some changes in the model and would like to train and run to test:
$ bash adhoc-train-and-run.sh
Running tests
$ bash modelapp/bootstrap-python-env.sh
$ . modelapp-python-env/bin/activate
$ py.test
Reverting a deployed version
In order to revert the deploy of some buggy code it will need install one more dependency to delete the tables created
(psql). For MacOS:
$ brew install postgresql
The script below will:
- delete the docker image from repository
- delete stack
- delete the tables in the database if they are created already
$ bash revert-deploy.sh -r $DOCKER_REPOSITORY_NAME \ -d $DB_NAME \ -u $DBMASTERUSER \ -p $DBPASSWORD \ -v myversionThe requirements to run it are
{1, 4, 5}andpsql.